This is documentation for the next version of Grafana Mimir documentation. For the latest stable release, go to the latest version.
Grafana Mimir deployment modes
Grafana Mimir offers two deployment modes to accommodate different operational requirements and scale needs. Choose the deployment mode that best fits your use case:
- Monolithic mode: Run all components in a single process for simple deployments.
- Microservices mode: Deploy components separately for maximum scalability and flexibility.
Configure the deployment mode using the -target parameter, which you can set via CLI flag or YAML configuration.
About monolithic mode
Monolithic mode runs all required components in a single process. This mode is ideal for getting started or running Grafana Mimir in a development environment.
To enable monolithic mode, set -target=all.
To see the complete list of components that run in monolithic mode, use the -modules flag:
./mimir -modulesThis diagram shows how Mimir works in monolithic mode:

Scale monolithic mode
You can horizontally scale monolithic mode by deploying multiple Mimir binaries with -target=all. This approach, shown in the following diagram, provides high availability and increased scale without the configuration complexity of microservices mode.

Note
Because monolithic mode requires scaling all Grafana Mimir components together, this deployment mode isn’t recommended for large-scale deployments.
About microservices mode
Microservices mode deploys each component in separate processes, enabling independent scaling and creating granular failure domains. Microservices mode is recommended for production environments.
Note
Even though the read path (query-frontend, querier, and store-gateway) runs separately from the write path (distributor and ingester), a healthy ring is typically required for successful queries. If the write components (distributor or ingester) are unavailable or unhealthy, the ring health check may fail, causing read queries to fail. Complete isolation of read versus write availability requires careful configuration of ring settings and failure tolerance.
Specifically, the querier consults the hash ring to discover ingesters before reading recent data from them. If ingesters are unhealthy or unavailable, the ring reflects that state and the querier may be unable to satisfy queries for recent data. Achieving true read/write isolation requires zone-aware replication and careful ring configuration so that the loss of write-path components does not reduce the ring below the quorum needed for reads. For more information, refer to Configuring zone-aware replication.
The following diagrams show how Mimir works in microservices mode using ingest storage and classic architectures. For more information about the two supported architectures in Grafana Mimir, refer to Grafana Mimir architecture.
Ingest storage architecture:
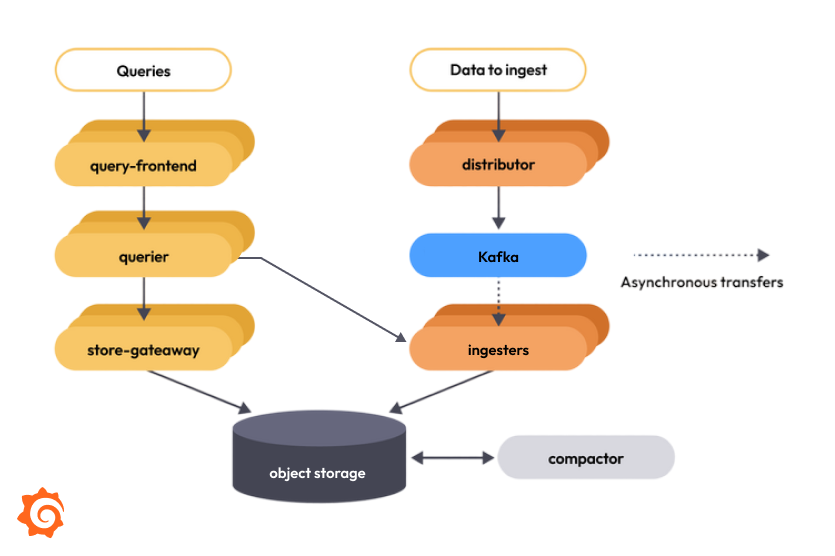
Classic architecture:

In microservices mode, each Grafana Mimir process is invoked with its -target parameter set to a specific Grafana Mimir component (for example, -target=ingester or -target=distributor). To get a working Grafana Mimir instance, you must deploy every required component. For more information about each of the Grafana Mimir components, refer to
Grafana Mimir advanced architecture.
To deploy Grafana Mimir in microservices mode, use Kubernetes and the mimir-distributed Helm chart.

